Linear and Logistic Regression, Part 2: Fitting the Models
Note: This post is part 2 of a 3-part series: part 1, part 2, part 3.
This is a blog post exploring how to fit linear and logistic regressions. First, note that linear and logistic regressors have different shapes. The shape of linear regression is a line, while the shape of logistic regression is a sigmoid:
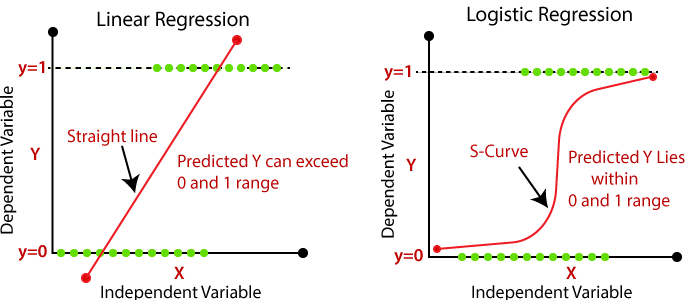
Also note that the same procedure can be used to fit a linear or logistic regressor, because the logistic equation can be rearranged to become a linear one.
Let $y^\prime = y$ for the case of a linear regression, and $y^\prime = \ln\left(\dfrac{1}{y}-1\right)$ for the case of a logistic regression. Then, we need to fit the regression to the following dataset:
So, we need to solve the matrix equation
We can put this in equation form and perform operations to isolate $\vec{\beta}\mathbin{:}$
This way of finding $\vec{\beta}$ involves using the pseudoinverse, $\left( \mathbf{X}^T \mathbf{X} \right)^{-1} \mathbf{X}^T.$ A matrix is not invertible unless it is square and we cannot guarantee this for $\mathbf{X},$ so we must take the pseudoinverse. By multiplying a $\mathbf{X}$ by its transpose, we can ensure that the result is square, and therefore, we can compute the inverse. Using the pseudoinverse minimizes the sum of squared error between the desired output $\vec{y}$ and the actual output $\mathbf{X}\vec{\beta}.$
For example, let’s fit a logistic regression to a medical data set
which takes the form
This data set is for a new medicine where the first column shows the amount of medicine A and the second medicine B. We have data on how well these medicines did when given to patients in differing amounts.
We can fit a logistic regression as follows:
Now we know the logistic $\beta$’s which are $\beta_0 = 1.567 \ \& \ \beta_1 = 0.278 \ \& \ \beta_2 = -0.640,$ so we plug in the variables $x_1, \ \& \ x_2$ into the equation:
Because very little changes from the linear regressor to the logistic regressor, my Python code for the logistic regressor inherits from the linear regressor class and changes only 2 things: it transforms the $\vec{y}$ using $y’ = \ln \left( \dfrac{1}{y}-1 \right)$ and puts the $\beta$’s in a sigmoid function rather than a linear function.
First, let’s go through the code for the linear regressor. We start by importing a Matrix class and a Dataframe class that I had written to help process data. Then, we initialize the linear regressor:
from matrix import Matrix from dataframe import DataFrame import math class LinearRegressor: def __init__(self, dataframe, dependent_variable='ratings'): self.dependent_variable = dependent_variable self.independent_variables = [column for column in dataframe.columns if column != dependent_variable] X_dataframe = dataframe.select.columns(self.independent_variables) y_dataframe = dataframe.select_columns([self.dependent_variable]) self.X = Matrix(X_dataframe.to_array()) self.y = Matrix(X_dataframe.to_array()) self.coefficients = {}
The way we would solve to get the $\vec{\beta}$’s is as follows:
def solve_coefficients(self): beta = (((self.X.transpose() @ self.X).inverse()) @ self.X.transpose()) @ self.y self.set_coefficients(beta) def set_coefficients(self, beta): for i, column_name in enumerate(self.dependent_variables): self.coefficients[column_name] = beta[i]
In order to find the actual prediction that the regression with the $\beta$’s, we need to plug the $\beta$’s into the regression function. For the linear regressor, this is just a linear function $f(x_1,\ldots, x_n)=\beta_0 + \beta_1 x_1 + \ldots + \beta_n x_n.$
def predict(self, input_dict): return self.regression_function(input_dict) def regression_function(self, input_dict): return sum([input_dict[key] * self.coefficients[key] for key in input_dict])
For the logistic regression, it’s the same process but we need to transform the $y$ values:
class LogisticRegressor(LinearRegressor): def __init__(self, dataframe, dependent_variable='ratings'): super().__init__(dataframe, dependent_variable='ratings') self.y = self.y.apply(lambda y: math.log(1/y - 1))
And we use a different regression function:
def regression_function(self, input_dict): linear_sum = sum([gathered_inputs[key] * coefficients[key] for key in gathered_inputs]) return 1 / (1 + math.e ** linear_sum)
This post is part 2 of a 3-part series. Click here to continue to part 3.
